Bedeutung:
Der Googlebot ist ein Crawler oder Webcrawler, der Google dabei hilft, Websites für seine Suchmaschine zu indexieren. Er ist ein wichtiger Bestandteil der Arbeitsweise von Google und wird ständig weiterentwickelt, um das Internet zu organisieren und zugänglich zu halten.
Wenn du eine Website betreibst, ist es wichtig zu verstehen, wie der Googlebot funktioniert, damit du deine Website für eine bessere Sichtbarkeit in den Suchergebnissen optimieren kannst. Wenn du verstehst, wie der Googlebot arbeitet, kannst du sicherstellen, dass deine Website richtig indiziert und für die Nutzer leicht zu finden ist.
Inhalt
Wie funktioniert der Googlebot?
Der Googlebot funktioniert grundsätzlich wie jeder andere Crawler. Er durchkämmt ständig das Internet und sammelt Daten über Websites, damit sie in der Suchmaschine richtig indexiert werden können.
Er beginnt mit einer Liste von Websites, die er bereits kennt, und folgt dann den Links, um neue Websites zu finden. Beim Crawlen des Webs sammelt der Googlebot Daten über jede Website, z. B. die Wörter auf der Seite, die Links auf der Seite und andere Informationen. Diese Daten werden dann verwendet, um zu bestimmen, wie die Websites in den Suchergebnissen eingestuft werden.
Der Googlebot entwickelt sich ständig weiter, um mit dem sich verändernden Web Schritt zu halten. Wenn neue Technologien auftauchen, passt sich der Googlebot an. So wird sichergestellt, dass die Nutzer immer die relevantesten und aktuellsten Ergebnisse finden, wenn sie in Google suchen.
Ich habe dir vier interessante Google-Quellen zu dem Thema zusammengesucht:
- Video von Matt Cutts (ehemals Leiter des Webspam-Teams bei Google): How search works (englisch)
- Google: How SEO works (en)
- Google Search Central: Dokumentation zur Google Suche (de)
- Google Search Central Podcast: How serving works, hreflang, and more!
Das Ranking für relevante Keywords zählt für die meisten SEO-Experten zu den entscheidenden Faktoren bei ihrer alltäglichen Arbeit.
Bezüglich Ranking spricht Google in seinem Podcast selbst von Serving: “The Ranking is actually happening in serving when we receive the queries and returning results from our index.”
Kurz: Das Ranking ist lediglich ein Schritt im gesamten Serving-Prozess von Google.
Um dir den im Podcast besprochenen Serving-Vorgang von der Suchanfrage der Nutzer bis zur Darstellung der Suchergebnisse besser zu veranschaulichen, habe ich dir folgende Liste vorbereitet:
- Query: Der Nutzer führt eine Suchabfrage (Nutzerabfrage) durch.
- Parsing: Die Verarbeitung der Abfrage erfolgt. Das Ziel ist, den jeweiligen Suchbegriff richtig zu interpretieren.
- Routing: Die interpretierte Suchanfrage wird an die unterschiedlichen Indizes von Google wie dem Web-Index, Video-, News- und Bilder-Index weitergeleitet
- Serving-Index: Jetzt durchsucht Google seine Indizes nach den passenden Dokumenten (verschiedene Dateiformate und Content-Arten).
- Ranking-System: Faktoren wie Aktualität, Relevanz und Content-Qualität sowie weitere 100te Signale werden bei der Reihenfolge der Ergebnisse berücksichtigt.
- Routing: Auf die Antworten der Indizes wird eine bestimmte Zeit gewartet. Zu späte Index-Antworten werden nicht berücksichtigt.
- Templating: Die Ergebnisse aus den Indizes werden für den Nutzer vorbereitet: JTemplate und CTemplate → Ergebnisseite in HTML
Wie die Google-Suche arbeitet, lässt sich auch optimal mit Informationsgrafiken veranschaulichen: Schritt für Schritt – vom Anfang bis zum Ende.
Infografiken: So funktioniert die Google-Suche
Wir haben dir einige Screenshots von der offiziellen Google-Webseite “So funktioniert die Google -Suche” aufbereitet.
Google crawlt das Web
Kleine Programme (auch Crawler, Webcrawler, Spider oder Googlebot genannt) durchsuchen das Web nach neuen oder aktualisierten Inhalten. Google nutzt für die verschiedenen Inhalte unterschiedliche Crawler. Dazu zählen:
- Googlebot für Bilder

- Googlebot für Nachrichten

- Googlebot für Videos

- Googlebot für Desktop-Computer

- Googlebot für Smartphone

Dabei folgen die Google-Crawler den internen und externen Verlinkungen (Hyperlinks) einer Webseite. Siehe diese Infografik:
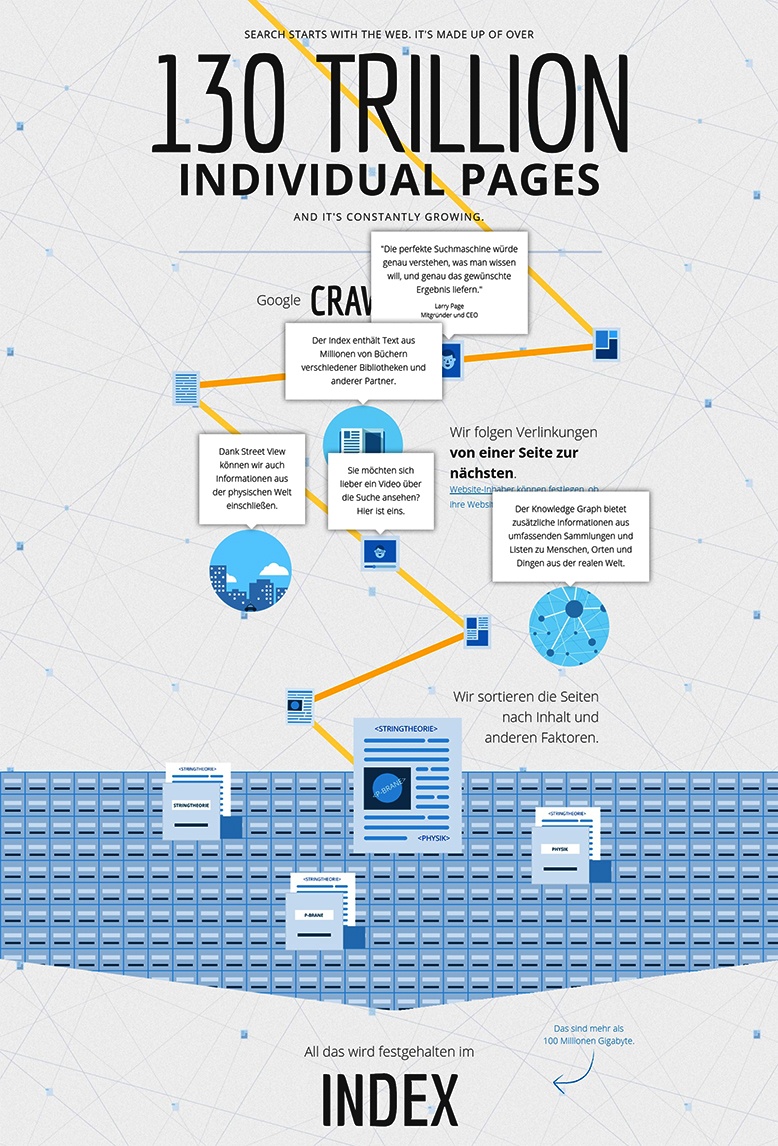
Wenn die gecrawlten Inhalte den Google-Richtlinien entsprechen, werden diese Inhalte im Suchmaschinenindex aufgenommen.
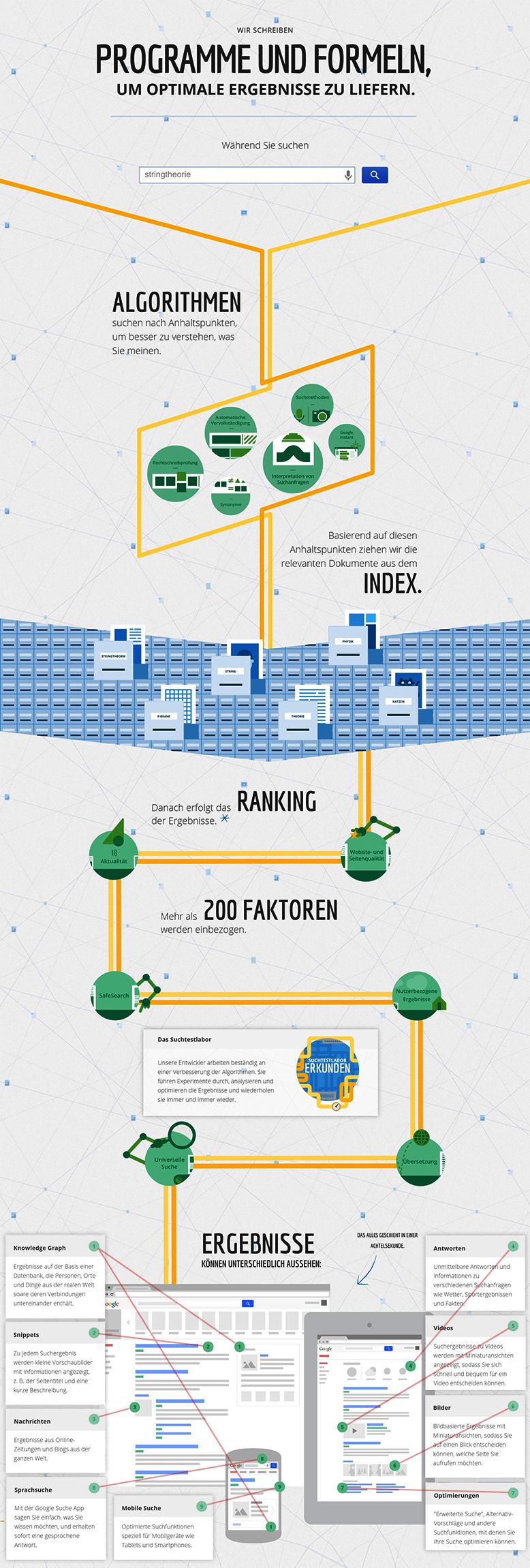
Google liefert Suchergebnisse
Nachdem User ihre Suchbegriffe in die Suchmaschinen eingeben und Suchanfragen starten, durchsucht Google seinen Index und präsentiert den Usern die besten Ergebnisse. Dabei berücksichtigt die Suchmaschine anhand bestimmter Algorithmen (dazu später mehr) über 200 Ranking-Faktoren, um den Suchenden nur relevante Resultate anzuzeigen.
Diese werden je nach Suchintention in unterschiedlicher Form in den Search Engine Result Pages (SERPs) angezeigt. Hierzu diese Infografik:
Google bekämpft Spam
Um tatsächlich die relevantesten Suchergebnisse zu liefern, werden durch automatisierte Prozesse wie Algorithmen und Filter minderwertige Inhalte herausgefiltert. Aber auch manuelle Maßnahmen werden ergriffen, wenn Spam-Inhalte auffallen oder direkt an Google gemeldet werden.
Auch dazu ein Screenshot:

Wie kann man dem Googlebot beim Indexieren seiner Website helfen?
Wenn du willst, dass deine Website vom Googlebot richtig indexiert wird, gibt es ein paar Dinge, die du tun kannst:
- Verwende klare und beschreibende Titel für deine Seiten.
- Verwende schlüsselwortreiche Beschreibungen für deine Seiten.
- Organisiere die Navigation auf deiner Website so, dass sich die Nutzer/innen leicht zurechtfinden.
- Achte darauf, dass das Design deiner Website responsive ist, damit sie auch auf mobilen Geräten gut angezeigt werden kann.
- Nutze die Google Search Console, um deine Sitemap einzureichen und den Fortschritt deiner Website in den Suchergebnissen zu verfolgen.
Wenn du diese Tipps befolgst, kannst du dem Googlebot helfen, deine Website effektiver zu crawlen und zu indexieren, was zu einer besseren Sichtbarkeit deiner Website in den Suchergebnissen führt.
Wie kann man verhindern, dass der Googlebot eine Webseite crawlt und indexiert?
Es kann Seiten oder Dateien geben, von denen man nicht will, dass sie in den Google-Index aufgenommen werden: Solche Seiten/Dateien können zum Beispiel folgende sein:
- Seiten/Dateien, die nur für eingeloggte Benutzer/innen bestimmt sind und sensible Informationen enthalten.
- Seiten, die dynamisch erstellt werden und doppelte Inhalte enthalten.
- Seiten, die sehr langsam sind und dazu führen können, dass der Googlebot eine Pause einlegt.
Wenn du verhindern willst, dass eine Seite oder Datei vom Googlebot gecrawlt wird, kannst du einen Eintrag in der robots.txt-Datei verwenden. Dadurch wird der Googlebot angewiesen, die Seite/Datei nicht zu crawlen.
Beispiel des robots.txt-Eintrages für ein PDF File:
User-Agent: Googlebot
Disallow: /datei.pdf
Bedeutung für SEO
Der Googlebot ist wichtig für SEO, weil er Google hilft, Websites zu indexieren. Wenn deine Website nicht richtig indexiert ist, erscheint sie nicht in den Suchergebnissen. Das kann zu Traffic- und Umsatzeinbußen führen.
Alles klar?
Solltest du noch Fragen zum Thema haben oder dir eine professionelle Unterstützung wünschen, dann melde dich bei uns. Schreibe eine E-Mail an
